14.1-: Introduction
Ganesh had recorded the marks of 26 children in his class in mathematics
Summative Assessment-1 in the register as follows.

In the data given in the list above organized? why or why not?
His teacher asked him to report on how his class students had performed in mathematics in their Summative Assessment - 1
Ganesh made the subsequent table to know the performance of his class

In the data given in the above table grouped or ungrouped?
He showed this table to his teacher and the teacher appreciated him for organizing the data to be understood easily.
We can see that most children have got marks between 76-100.
Do you think Ganesh should have used a smaller range? Why or why not?
In the previous class, you had learned about the difference between grouped and ungrouped data as well as how to present this data in the form of tables.
You had also learned to calculate the mean value for ungrouped data. Let us recall this learning and then learn to calculate the mean, median and mode for grouped data.
14.2 Mean of Ungrouped data
As we know the mean (or average) of observations is the sum of the values of all the observations divided by the total number of observations.
Let x1 , x2 ,. . ., xn be observations with respective frequencies f1 , f2 , . . ., fn .
This means that observation x1 occurs f1 times, x2 occurs f2 times, and so on.
Now, the sum of the values of all the observations = f1 x1 + f2 x2 + . . . + fn xn , and the number of observations = f1 + f2 + . . . + fn .
So, the mean x of the data is given by
x = f1 x1 + f2 x2 ..........fn xn
f1 + f2+.........+fn
Recall that we can write this in short, using the Greek letter ∑ which means the summation
i.e., x = ∑ f1x1
∑ f1
*****************************************
Example-1. The marks obtained in mathematics by 30 students of Class X of a certain school are given in the table below. Find the mean of the marks obtained by the students

Solution : Let us re-organize this data and find the sum of all observations.

So,
x = ∑ f1x1
∑ f1
= 1779
30
= 59.3
Therefore, the mean marks are 59.3
In most of our real-life situations, data is usually so large that to make a meaningful study, it needs to be condensed as grouped data. So, we need to convert ungrouped data into grouped data and devise some method to find its mean.
Let us convert the ungrouped data of Example 1 into grouped data by forming class intervals of width, say 15.
Remember that while allocating frequencies to each class-interval, students whose score is equal to in any upper class-boundary would be considered in the next class,
e.g., 4 students who have obtained 40 marks would be considered in the class-interval 40-55 and not in 25-40.
With this convention in our mind, let us form a grouped frequency distribution table.

Now, for each class-interval, we require a point which would serve as the representative of the whole class.
It is assumed that the frequency of each class-interval is centered around its mid-point.
So, the mid-point of each class can be chosen to represent the observations falling in that class and is called the class mark.
Recall that we find the classmark by finding the average of the upper and lower limit of the class.
Classmark -:
= Upper-class limit + Lower class limit
2
For the class 10-25, the classmark is
10+25 = 17.5.
2
Similarly, we can find the class marks of the remaining class intervals. We put them on the table. These class marks serve as our Xi's.
We can now proceed to compute the mean in the same manner as in the previous example.

The sum of the values in the last column gives us Σ f1 x1 .
So, the mean x of the given data is given by
x = ∑ f1x1
∑ f1
= 1860/30
= 62
This new method of finding the mean is known as the Direct Method.
We observe that in the above cases we are using the same data and employing the same formula for calculating the mean but the results obtained are different.
In example (1), 59.3 is the exact mean and 62 is the approximate mean. Can you think why this is so?
Think - Discuss
1. The mean value can be calculated from both ungrouped and grouped data. Which one do you think is more accurate? Why?
2. When it is more convenient to use grouped data for analysis?
Sometimes when the numerical values of x1 and f1 are large, finding the product of x1 and f1 becomes tedious and time-consuming.
So, for such situations, let us think of a method of reducing these calculations.
We can do nothing with the fi's, but we can change each xi to a smaller number so that our calculations become easy.
How do we do this?
What is about subtracting a fixed number from each of these xi 's?
Let us try this method for the data in example1.
The first step is to choose one among the xi 's as the assumed mean, and denote it by 'a'.
Also, to further reduce our calculation work, we may take 'a' to be that xi which lies in the center of x1, x2, ..., xn.
So, we can choose a = 47.5 or a = 62.5. Let us choose a = 47.5.
The second step is to find the deviation of ‘a’ from each of the xi 's, which we denote as di i.e.,
di = xi – a
= xi – 47.5
The third step is to find the product of di with the corresponding fi , and take the sum of all the fi di ’s.
These calculations are shown in the table given below

So, from the above table, the mean of the deviations
d = Σ fi di
Σfi
_ _
Now, let us find the relation between d and x
Since, in obtaining di we subtracted 'a' from
_
each xi so, in order to get the mean x we need
_
to add 'a' to d.
This can be explained mathematically as:
Mean of deviations,
_
d = Σ fi di
Σ fi
So,
_
d = Σ fi(xi-a)
Σ fi
= Σ fi xi - Σ fi*a
Σ fi Σ fi
_
= x - a Σ fi
Σ fi
_ _
d = x - a
Therefore
_
x = a + Σ fi*di
Σ fi
Substituting the values of a, Σfi*di and Σfi from the table, we get
x = 47.5 + 435
30
= 47.5 + 14.5
= 62
Therefore, the mean of the marks obtained by the students is 62.
The method discussed above is called the Assumed Mean Method.
Observe that in the table given below the values in Column 4 are all multiples of 15.
So, if we divide all the values of Column 4 by 15, we would get smaller numbers which we then multiply with fi.
(Here, 15 is the class size of each class interval).
So, let
ui = xi - a
h
where a is the assumed mean and h is the class size.
Now, we calculate ui in this way and continue as before (i.e., find di*ui and then Σfi*ui).
Taking h = 15.
[ Generally size of the class is taken as h but it need not be size of the class always]
_
Let u = Σ fi*ui
Σ fi

_
Here , again let us find the relation between u
_
and x
We have
ui = xi - a
h
So
_
u = Σ fi*ui
Σ fi
So
_
u = Σ fi( xi - a)
h
---------------
Σfi
= 1 [ Σ fi*xi - Σ fi*a]
h Σ fi Σ fi
_
= 1 ( x - a)
h
or
_ _
h* u = x - a
_ _
x = a + h*u
Therefore,
_
x = a + h[ Σ fi*ui ]
Σ fi
or
_
x = a + (Σ fi*ui) * h
Σ fi
Substituting the values of a, Σ fi*ui and Σ fi from the table.
we get
_
x = 47.5 + 15 *(29/30)
= 47.5 + 14.5
= 62
So, the mean marks obtained by a student are 62.
The method discussed above is called the
Step-deviation method.
We note that :
*) The step-deviation method will be convenient to apply if all the di's have a common factor.
*) The mean obtained by all the three methods is the same.
*) The assumed mean method and step-deviation method are just simplified forms of the direct method.
_ _
*) The formula x = a + h*u still holds if a and h are not as given above, but are any non-zero numbers such that
ui = xi - a
h
*****************************************
Example-2. The table below gives the percentage distribution of female teachers in the primary schools of rural areas of various states and union territories(U.T) of India. Find the mean percentage of female teachers using all the three methods.

sol) Let us find the class marks xi of each class, and put them in a table
Here we take a = 50, h=10,
then di = xi - 50 and
ui = xi - 50
10
we now find di and ui and put them in the table

From the table above, we obtain
Σ fi = 35,
Σ fi*xi = 1390
Σ fi*di = -360
Σ fi*ui = -36
Using the direct method
_
x = Σ fi*xi
Σ fi
= 1390
35
= 39.71
(*) Using the assumed mean method
_
x = a + Σ fi*di
Σ fi
= 50 + (-360)
35
= 50 - 10.29 = 39.71
(*) Using the step-deviation method
_
x = a + [Σ fi*ui ] * h
Σ fi
= 50 + (-36) * 10
35
= 39.71
Therefore, the mean percentage of female teachers in the primary schools of rural areas is 39.71
Even if the class sizes are unequal, and xi are large numerically, we can still apply the step-deviation method by taking h to be a suitable divisor of all the di's
*****************************************
Example-3. The distribution below shows the number of wickets taken by bowlers in one-day cricket matches. Find the mean number of wickets by choosing a suitable method. What does the mean signify?

sol) Here, the class size varies, and the xi's are large.
Let us still apply the step-deviation method with
a= 200 and
h = 20.
Then, we obtain the data as given in the table.

So
_
x = a + (Σ fi*ui) * h
Σ fi
= 200 + (-106) * 20
45
= 200 - 47.11
= 152.89
Thus, the average number of wickets taken by these 45 bowlers in one-day cricket is 152.89
****************************************
Exercise-14.1
1) A survey was conducted by a group of students as a part of their environment awareness program, in which they collected the following data regarding the number of plants in 20 houses in a locality. Find the mean number of plants per house.

Sol) It is assumed that the frequencyof every class-interval is centered
around its mid-point. So, the mid-pointof every class is often chosen to represent the
Mean no. of plants are = 8.1
This new method of finding the mean is known as the Direct Method
******************************************************
2. Consider the following distribution of daily wages of 50 workers in a factory.

Find the mean daily wages of the workers of the factory by using an appropriate method.
Sol) we have

Where Assumed mean (A) = 325
h = class interval = 250-200 = 50

(*) Mean
=
= 325 + 50* (-12/50)
= 325 +[ -12]
= 325 - 12
= 313
The method above is named the Step-deviation method.
Note that:-
(*) The step-deviation method will be convenient to apply if all the di's have a common factor.
in the above table, the di's value have the same factor '50'
-100/50 = - 20
-50/50 = -1
50/50=1
100/50 = 2
(*) The assumed mean method and step-deviation method are just simplified sorts of the
direct method.
******************************************************
3. The following distribution shows the daily pocket allowance of youngsters of a neighborhood. The mean pocket allowance is 18. Find the missing frequency f.

sol)


18 = (752 + 20f)
44 + f
18(44 +f) = 752 + 20f
792 + 18f = 752 + 20f
2f = 40
f = 20
*********************************************************
4. Thirty women were examined during a hospital by a doctor and their heartbeats per minute were recorded and summarised as shown. Find the mean heartbeats per minute for these women, choosing an appropriate method.

sol)

Assumed mean(A) = 75.5
class interval(h) = 68-65 = 3
Xi = (Upper + Lower class)
2
= (65 + 68)
2
= 66.5
Di = Xi - A = 66.5 - 75.5 = -9
Ui = Xi - a / h = ( 66.5 - 75.5) / 3 = -9/3 = -3
Fi Ui =( 2 * -3) = -6
Σ Fi= 30
Σ Fi Ui = 4
(*) Mean-:
= 75.5 + 3 * (4/30)
= 75.5 + 0.4
= 75.9
Therefore, the mean heartbeats per minutes of women are = 75.9
**************************************************************
5. In a retail market, fruit vendors were commercialism oranges unbroken in packing baskets. These baskets contained varied numbers of oranges. the subsequent was the distribution of
oranges.

find the mean number of oranges kept in each basket. Which method of finding the mean did you choose?
sol)

Assumed mean (A) = 22
Class interval(h) = 15 - 10 = 5
𝚺 Fi = 400
𝚺 Fi Ui = 25
(*) Mean:-
We apply step-deviation method as all Di's have common factor "5" and also Xi and Fi are numerically large numbers
= 22 + 5 [25/400]
= 22 + 5(1/16)
= 22 + 5/16
= 22 + 0.31
Therefore, Mean = 22.31
***************************************************************
6. The table below shows the daily expenditure on the food of 25 households in a locality.

Find the mean daily expenditure on food by a suitable method.
sol) (*) Classmark (Xi):-
(1) (100 + 150) / 2 = 125
so on...
(5) (300 + 350) / 2 = 325
(*) Di = Xi - A
(1) Di = 125 - 225 = -100
so on...
(5) Di = 325 - 225 = 100
(*) Ui = (Xi - A) / h
(1) (125 - 225) / 50 = (-100)/50 = -2
so on...
(5) (325 - 225) / 50 = (100) / 50 = 2
(*) Fi Ui:-
(1) 4 * (-2) = -8
so on...
(5) 2 * 2 = 4

Assumed mean (A) = 225
Class interval (h) = 150 - 100 = 50
𝚺 Fi = 25
𝚺 Fi Ui = -7
(*) Mean:-
= 225 + 50 *(-7/25)
= 225 + 2 * (-7)
= 225 - 14
Mean (x)= 211 rs is the daily expenditure on food
***********************************************
7. To find out the concentration of SO2 in the air (in parts per million, i.e., ppm), the data was collected for 30 localities in a certain city and is presented below:

Find the mean concentration of SO2 in the air.
Sol) Classmark (Xi) :-
(1) (0.00 + 0.04) / 2
= 0.02
so on...
(5) ( 0.16 + 0.20) / 2
= 0.22
(*) Fi Xi :-
(1) 4 * 0.02 = 0.08
So on...
(5) 2 * 0.20 = 0.44

(*) Mean:-

X = 2.96 / 30
remove a decimal point from 2.96 and transfer it to the denominator
X = 296 / 3000 divide by "3" we get,
=> 98.67 / 1000
Transfer 1000 to numerator we get
=> 0. 09867 or 0.099
Mean concentration of SO2 in the air is = 0.099 ppm
We used this method as Fi and Xi is easier to calculate and sum
********************************************************
8. A class teacher has the following attendance record of 40 students of a class for the whole term. Find the mean number of days a student was present out of 56 days in the term.

sol)
(*) Classmark(Xi)-:
(1) Xi = (35 +38) / 2 = 36.5
so on...
(7) Xi = (53+56)/2 = 54.5
(*) Xi Fi :-
(1) 36.5 * 1 = 36.5
so on...
(7) 54.5 *11 = 599.5


= 1961 / 40
= 49.025 or 49
Thus, the mean no.of days a student was present is 49.
OPtional :-
We will use a direct method as the class interval is not the same

= > 499 / 40
=> 12.48 is the mean number of days a student was absent
*********************************************************
9. The following table gives the literacy rate (in percentage) of 35 cities. Find the mean literacy rate.

Sol) ClassMark (Xi):-
(1) (45 + 55) / 2 = 50
so on...
(5) (85+75) / 2 = 90
Assumed mean(A) = 70
Class interval(h) = 55 - 45 = 10
(*) Di = Xi - A
(1) 50 - 70 = -20
so on...
(5) 90-70 = 20
(*) Ui = (Xi - A)/h
(1) -20 / 10 = -2
so on...
(5) 20/10 = 2
(*) Fi * Ui
(1) 3 * -2 = -6
so on...
(5) 3 *2 = 6

𝚺 Fi = 35
𝚺 Fi Ui = -2

=> 70 + 10[ -2 / 35]
=> 70 + [-20/35]
=> 70 + [-4/7]
=> 70 - 0.57
=> 69.43 is the Mean literacy rate
****************************************
(*) Mode
A mode is that value among observations which occur most frequently.
Before learning about calculating the mode of grouped data let us first recall how we found the mode for ungrouped data through the following example
Example-4. The wickets taken by a bowler in 10 cricket matches are as follows : 2,6,4,5,0,2,1,3,2,3.
Find the mode of the data.
sol) let us arrange the observations in order i.e.,
0,1,2,2,2,3,3,4,5,6
Clearly, 2 is the number of wickets taken by the bowler in the maximum number of matches(i.e., 3 times). So, the mode of this data is 2.
In a grouped frequency distribution, it is not possible to determine the mode by looking at the frequencies.
Here, we can only locate a class with the maximum frequency, called the modal class.
The mode is a value inside the modal class, and is given by the formula.

******************************************
Example-5 : A survey conducted on 20 households in a locality by a group of students resulted in the following frequency table for the number of family members in a household.

Find the mode of this data
sol) Here the maximum class frequency is 8, and the class corresponding to this frequency is 3-5.
So, the modal class is 3-5.
Now,
modal class = 3-5,
boundary limit(L) of modal class = 3
class size(h) = 2
frequency of the modal class(f1) = 8
frequency of class preceding the modal class(f0) = 7
frequency of class succeeding the modal class (f2) = 2.
Now , let us substitute these values in the formula
= 3 + ( 8 - 7 ) * 2
(2*8) - 7 - 2
= 3 + 2 = 3.286
7
Therefore, the mode of the data is 3.286
*****************************************
Example-6 . The marks distribution of 30 students in a mathematics examination are given in the adjacent table.
Find the mode of this data. Also compare and interpret the mode and the mean.

sol). Since the maximum number of students (i.e., 7) have got marks in the interval,40-55
the modal class is 40 - 55
The lower boundary(L) of the modal class = 40.
The class size(h) = 15.
The frequency of modal class(f1) = 7
The frequency of the class preceding the modal class(f0) = 3.
The frequency of the class succeeding the modal class (f2) = 6.
Now , using the formula :
= 40 + ( 7 - 3 ) * 15
(2*7) - 6 - 3
= 40 + 12 = 52
Interpretation : The mode marks is 52.
Now, from example 1, we know that the mean marks is 62.
So, the maximum number of students obtained 52 marks, while on an average a student obtained 62 marks.
*****************************************
Exercise-14.2
1. The following table shows the ages of the patients admitted to a hospital for a year:

Find the mode and the mean of the data given above. Compare and interpret the two measures of central tendency.
sol) Class Mark:-
(1) 5+15 / 2 = 10
(2) 15 +25 / 2 = 20
(3) 25+35 / 2 = 30
(4) 35+45/2 = 40
(5) 45 + 55/2 = 50
(6) 55 +65 / 2 = 60
(*) Fi * Xi:-
(1) 6 * 10 = 60
(2) 11 * 20 = 220
(3) 21 * 30 = 630
(4) 23 * 40 = 920
(5) 14 * 50 = 700
(6) 5 * 60 = 300

=> 2830 / 80
Mean(X) = 35.375
(*) Mode:-


Modal class
= Interval with higher frequency
= 35 -45
Where L = Lower limit of modal class = 35
h = class-interval = 15-5=10
F1 = frequency of the modal class = 23
F. = frequency of the class before modal class = 21
F2 = frequency of the class after modal class = 14
Mode = 35 + 23-21 * 10
2(23) -21-14
= 35 + 2 * 10
46-35
= 35 + (2/11) * 10
= 35 + 1.8
Mode = 36.8
***************************************************
2. The following data gives the information on the observed lifetimes (in hours) of 225 electrical components :

Determine the modal lifetimes of the components.
sol) Modal class = Interval with the highest frequency = 60-80
h = class-interval = 20-0 = 20
L= lower limit of modal class = 60
F1=frequency of the modal class = 61
F.=frequency of the class before modal class = 52
F2=frequency of the class after modal class = 38


Mode = 60 + 61-52 *20
2(61)-52-38
= 60 + 9 *2
122 - 90
= 60 + (9/32) * 20
= 60 + (9/8) * 5
= 60 + (45/8)
=60 + 5.62
Mode = 65.62
********************************
3. The following data gives the distribution of total monthly household expenditure of 200 families of a village. Find the modal monthly expenditure of the families. Also, find the mean monthly expenditure :

Sol)

Modal class = Interval with the highest frequency = 1500-2000
h = class-interval = 1500-1000 = 1500
L= lower limit of modal class = 1500
F1=frequency of the modal class = 40
F.=frequency of the class before modal class = 24
F2=frequency of the class after modal class = 33

Mode = 1500 + 40-24 *500
2(40)-24-33
=> 1500 + 16 *500
80-57
=> 1500 + (16/23) * 500
=> 1500 + 347.826
=> 1847.83.
Therefore, the modal monthly expenditure of families is Rs.1847.83
Now, Mean:-
Classmark(Xi) :-
(1) (1000+1500)/2 = 1250
(2) (1500+2000)/2 = 1750
(3) (2000+2500)/2 = 2250
(4) (2500+3000)/2 = 2750
(5) (3000+3500)/2 = 3250 =A
(6) (3500+4000)/2 = 3750
(7) (4000+4500)/2 = 4250
(8) (4500+5000)/2 = 4750
(*) Di = Xi - A
(1) 1250 - 3250 = -2000
(2) 1750-3250= -1500
(3) 2250-3250= -1000
(4) 2750-3250= -500
(5) 3250-3250=0
(6) 3750-3250= 500
(7) 4250-3250=1000
(8) 4750-3250=1500
(*) Ui = Di /h or (Xi-3250)/500
(1) -2000/500 = -4
(2) -1500/500= -3
(3) -1000/500= -2
(4) -500/500=1
(5) 0/500 = 0
(6) 500/500 = 1
(7) 1000/500=2
(8) 1500/500=3
(*) Fi * Ui:-
(1) 24 * -4 = -96
(2) 40 * -3 = -120
(3) 33 * -2 = -66
(4) 28 * -1= -28
(5) 30 * 0 = 0
(6) 22 *1 = 22
(7) 16 * 2 = 32
(8) 7 *3 = 21

𝚺 Fi = 200
𝚺 Fi Ui = 235
Assumed mean(A) = 3250
Class interval(h) = 1500-1000=500
(*) Mean:-
=> 3250 + 500 * ( -235/200)
=> 3250 + 5 *( -235/2)
=> 3250 - (1175/2)
=> 3250 - 587.5
=> 2662.5
.^. Mean expenditure =2662.5
*******************************************************
4). The following distribution gives the state-wise, teacher-student ratio in higher secondary schools of India. Find the mode and mean of this data. Interpret the two measures.

Sol) Class interval(h) = 20-15 = 5

(*) Modal class = interval with highest frequency = 30-35
L = Lower limit of modal class =30
F1 =frequency of modal class = 10
F. = frequency of class before modal class = 9
F2 = frequency of class after modal class = 3
= 30 + 10-9 * 5
2(10)-9-3
= 30 + 1 *5
20-12
=30 + (5/8)
= 30 + 0.625
Mode = 30.625
(!!) Mean:-
(*) Class mark (Xi):-
(1) (15+20)/2 = 17.5
(2) (20+25)/2 = 22.5
(3) (25+30)/2= 27.5
(4) (30+35)/2= 32.5
(5) (35+40)/2= 37.5
(6) (40+45)/2= 42.5
(7) (45+50)/2= 47.5
(8) (50+55)/2= 52.5
(*) Di = Xi - A or Xi - 37.5
(1) 17.5-37.5 = -20
(2) 22.5-37.5 = -15
(3) 27.5-37.5= -10
(4) 32.5-37.5= -5
(5) 37.5 - 37.5 = 0
(6) 42.5 - 37.5= 5
(7) 47.5- 37.5 = 10
(8) 52.5 - 37.5 = 15
(*) Ui = (Xi-A)/h or (Di/h)
(1) -20/5 = -4
(2) -15/5= -3
(3) -10/5 = -2
(4) -5/5 = -1
(5) 0/5 = 0
(6) 5/5 = 1
(7) 10/5 = 2
(8) 15/3 = 3
(*) Fi * Ui
(1) 3*-4 = -12
(2) 8 *-3 = -24
(3) 9*-2 = -18
(4) 10*-1 = -10
(5) 3*0=0
(6) 0*1=0
(7) 0*2=0
(8) 2*3=6

(*) Mean :-
Class interval(h) = 20-15 = 5
Assumed mean(A)= 37.5
𝚺 Fi = 35
𝚺 Fi * Ui = -58
=> 37.5 +5 (-58/35)
=> 37.5 - (58/7)
=> 37.5 - 8.286
.^. Mean (X)= 29.214
Student-teacher ratio=Mode=30.625
Student-teacher ratio=Mean=29.214
********************************
5. The given distribution shows the number of runs scored by some top batsmen of the world in one-day international cricket matches.

Find the mode of the data.
sol) Modal class= interval with highest frequency= 4000-5000

L = lower limit of modal class = 4000
Class interval(h) = 4000-3000=1000
F1 = Frequency of the modal class = 18
F. = frequency of class before modal class = 4
F2=frequency of class after modal class=9
=> 4000 + 18-4 *1000
2(18)-4-9
=> 4000 + 14 *1000
36-13
=> 4000+14000
23
=> 4000+ 608.69
.^.Mode= 4608.69
**********************************
6. A student noted the number of cars passing through a spot on a road for 100 periods, each of 3 minutes, and summarized this in the table given below.

Find the mode of the data.
sol) Modal class= interval with highest frequency = 40-50.

L=Lower limit of modal class=40
Class interval(h)=10-0=10
Frequency of modal class(F1) = 20
Frequency of class before modal class(F.) = 12
Frequency of class after modal class(F2) = 11
=> 40 + 20-12 *10
2(20)-12-11
=> 40 + 8 *10
40-23
=> 40 + (80/17)
=> 40 + 4.7
.^. Mode = 44.7
******************************************
(*) Median of Grouped data
Median is a measure of central tendency which gives the value of the middle-most observation in the data.
Recall that for finding the median of un-grouped data. we first arrange the data values or the observation in ascending order.
Then, if n is odd, the median is the
(n + 1)th observation and
2
If n is even, then the median will be the average of the
(n)th and ( n + 1)th observations.
2 2
Suppose, we have to find the median of the following data, which is about the marks, out of 50 obtained by 100 students in a test :

First, we arrange the marks in ascending order and prepare a frequency table as follows :

Here n = 100, which is even. The median will be the average of the
(n )th and the
2
(n + 1)th
2
observations, i.e., the 50th and 51th observations. To find the position of these middle values, we construct cumulative frequency.

Now we add another column depicting this information to the frequency table above and name it as cumulative frequency column.
From the table above, we see that :
50 th observation is 28
51 th observation is 29
median = 28 +29 = 28.5
2
Remark : Column 1 and column 3 in the above table are known as Cumulative Frequency Table.
The median marks 28.5 conveys the information that about 50% students obtained marks less than 28.5 and another 50% students obtained marks more than 28.5
Consider a grouped frequency distribution of marks obtained, out of 100, by 53 students, in a certain examination, as shown in adjacent table.

From the table, try to answer the following questions:
How many students have scored marks less than 10? The answer is clearly 5.
How many students have scored less than 20 marks?
Observe that the number of students who have scored less than 20 include the number of students who have scored marks from 0-10 as well as the number of students who have scored marks from 10-20.

So the total number of students with marks less than 20 is 5+3, i.e., 8.
We say that the cumulative frequency of the class 10-20 is 8.
Similarly, we can compute the cumulative frequencies of the other classes, i.e., the number of students with marks less than 30, less than 40,...., less than 100.
This distribution is called the cumulative frequency distribution of the less than type.
Here 10,20,30.....100, are the upper boundaries of the respective class intervals.
We can similarly mark the table for the number of students with scores more than or equal to 0(this number is same as sum of all the frequencies), more than above sum minus the frequency of the first class interval),
more than or equal to 20 ( this number is same as the sum of all frequencies minus the sum of the frequencies of the first two class intervals), and so on.
We observe that all 53 students have scored marks more than or equal to 0.

Since there are 5 students scoring marks in the interval 0-10, this means that there are 53-5=48 students getting more than or equal to 10 marks.
Continuing in the same manner, we get the number of students
scoring 20 or above as 48-3 =45
or above as
45-4 = 41, and so on,as shown in the table.
This table above is called a cumulative frequency distribution of the more than type.
Here 0,10,20...,90 give the lower boundaries of the respective class intervals.
Now, to find the median of grouped data, we can use of any of these cumulative frequency distributions.
Now in a grouped data, we may not be able to find the middle observation by looking at the cumulative frequencies as the middle observation will be some value in a class interval.
It is, therefore, necessary to find the value inside a class that divides the whole distribution into two halves. But which class should this be?
To find this class, we find the cumulative frequencies of all the classes and (n/2).
We know locate the class whose cumulative frequency (n/2) for the first time.

This is called the median class.
In the distribution above,
n = 53.
n = 26.5
2
Now 60-70 is the class whose cumulative frequency 29 is greater than (and nearest to)
n , i.e., 26.5
2
Therefore, 60-70 is the median class.
After finding the median class, we use the following formula for calculating the median.

525 = 500 + (50-36-x) * 100
20
525 - 500 = (14-x)*5
25 = 70-5x
5x = 70-25 = 45
x = 9
Therefore, from (1),
we get 9 + y = 24
i.e., y = 15

Note : The median of grouped data with unequal class sizes can also be calculated.
*****************************************
Exercise-14.3
1. The following frequency distribution gives the monthly consumption of electricity of 68 consumers of a locality. Find the median, mean and mode of the data and compare them.

sol) Assumed mean(A) = 135
Class-interval(h) = 85-65 = 20
(*) Mean:-
(*) Classmark(Xi):-
(1) (65+85)/2 = 75
(2) ( 85+105)/2= 95
(3) (105+125)/2 = 115
(4) (125+145)/2= 135=A
(5) (145+165)/2 = 155
(6) (165+185)/2 = 175
(7) ( 185+205)/2 = 195
(*) Di= Xi-A (OR) Xi-135
(1) 75-135=-60
(2) 95-135=-40
(3) 115-135= -20
(4) 135-135=0
(5) 155-135=20
(6) 175-135=40
(7) 195-135=60
(*) Ui = Di/h (or) (Xi-A)/h (or) (Xi-135)/20
(1) -60/20 = -3
(2) -40/20 = -2
(3) -20/20 = -1
(4) 0/20 = 0
(5) 20/20 = 1
(6) 40/20 = 2
(7) 60/20 = 3
(*) fi*Ui:-
(1) 4*-3 = -12
(2) 5*-2 = -10
(3) 13*-1 = -13
(4) 20*0=0
(5) 14*1 = 14
(6) 8*2 = 16
(7) 4*3 = 12

𝚺fi = 68
𝚺 fi*Ui = 7
=> 135 + 20 *(7/68)
=> 135 + 2.05
.^. Mean = 137.05
(2) Median:-
n= 𝚺f1 = 68
n/2 = 68/2 = 34

Median class= 125-145
lower limit of median class(L)=125
class-interval(h) = 85-65=20
cumulative frequency of the class before median class(cf) = 22
frequency of the median class(f)=20

=125+34-22*20
20
= 125+(12/20) * 20
= 125+ 12
.^. median = 137
(*)Mode :-

modal class=interval with highest frequency = 125-145
lower limit of modal class(L)=125
class-interval(h) = 85-65=20
frequency of the modal class(f1)=20
frequency of class before modal class(f0)=13
frequency of class after modal class(f2) = 14
=125 +34-22*20
20
=125+(12/20)*20
=125+12
.^. Mode = 137
********************************************
2. If the median of 60 observations, given below is 28.5, find the values of x and y.

sol) Given Median = 28.5
so, 20-30 is the median class
(*) Given :- median of 60 observation
so, n= 𝚺fi=60
n/2= (60/2) = 30

lower limit of median class(L)= 20
class-interval(h) = 10-0=10
cumulative frequency of the class before median class(cf) = 5+x
frequency of the median class = 20
28.5 = 20 +30-(5+x)*10
20
28.5 = 20 + 25-x *10
20
28.5 = 20 +(25-x)
2
28.5 - 20 = (25-x) / 2
8.5 * 2 = 25-x
17 = 25-x
x = 25-17
.^. x = 8 --------(1)
Also,

𝚺fi = 5+x+20+15+y+5
60 = 45 + x +y
substitute (1) x = 8
60 = 45+8+y
60-53=y
7=y ------(2)
Hence , X= 8, y = 7
*********************************************
3. A life insurance agent found the following data about the distribution of ages of 100
policy holders. Calculate the median age.
[Policies are given only to persons having age 18 years onwards but less than 60 years.]

sol) Given = n = 𝚺fi =100
n/2 = (100/2) = 50
(*) Normal Form:-

.^. Median class = 35-40

lower limit of median class(L)= 35
Class-interval(h) = 25-20=5
cumulative frequency of the class before median class(cf) = 45
frequency of the median class(f) = 33
= 35 +50-45*5
33
= 35 +(5/33) * 5
= 35 + 0.76
Median = 35.76
***********************************
4. The lengths of 40 leaves of a plant are measured correct to the nearest millimeter, and the data obtained is represented in the following table :

Find the median length of the leaves. (Hint-: The data needs to be converted to continuous classes for finding the median since the formula assumes continuous classes. The classes then change to 117.5 - 126.5, 126.5 - 135.5, ..., 171.5 - 180.5.)
sol) Given:- n = 𝚺 fi = 40
(n/2) = (40/2) =20
(*) Dis-continuous
Observe that class interval
=> 118-126 and 127-135 is discontinuous
We can see the difference is 127-126=1
so, Diff/2 = 1/2 = 0.5
.^. we add 0.5 to each upper-limit and subtract 0.5 from lower-limit to make the class interval continuous. the frequency will remain same.
(*) Continuous :-

Median= 144.5-153.5
lower limit of median class(L)= 144.5
class-interval(h) = 126.5-117.5= 9
cumulative frequency of the class before median class(cf)=17
frequency of the median class(f) = 12
= 144.5 + 20-17 *9
12
= 144.5 + (3/12)*9
= 144.5 + 2.25
.^. median = 146.75
************************************
5. The following table gives the distribution of the life-time of 400 neon lamps

Find the median lifetime of a lamp.
sol) Given:- n = 𝚺 fi = 400
(n/2) = (400/2) = 200
Median class= 3000-3500

Lower limit of median class(L) = 3000
class-interval(h) = 2000-1500=500
cumulative frequency of the class before median class(cf) = 130
frequency of the median class(f) = 86
=3000 + 200-130 *500
86
= 3000 +(70/86) * 500
= 3000 + (0.81) * 500
= 3000 + 406.97
.^. Median life of lamp = 3406.97hrs
*************************************
6. 100 surnames were randomly picked up from a local telephone directory and the frequency distribution of the number of letters in the English alphabet in the surnames was obtained as follows

Determine the median no of letters in the surnames. Find the mean no of letters in the surnames? Also, find the modal size of the surnames.
Sol) Given:- n = 𝞢 Fi = 100
(n/2) = 100/2 = 50
.^. 7-10 is the median class

Lower limit of median class(L) = 7
Class-interval(h) = 4-1=3
cumulative frequency of the class before median class(CF) = 36
Frequency of the median class(F) = 40
=> 7 +50-36*3
40
=> 7+ (14/40) *3
=> 7+ (0.35)*3
=> 7+ 1.05
.^. Median = 8.05
(*) Finding Mode:-

Modal class= interval with highest frequency= 7-10
Class-interval(h) = 4-1=3
frequency of the modal class(f1)=40
frequency of class before modal class(f.) = 30
frequency of class after modal class(f2) = 16

=7 + 40-30 *3
2(40)-30-16
=> 7 + 10 *3
80-46
=> 7+ (10/34) *3
=> 7+ (0.29)*3
=> 7+ 0.88
.^. Mode = 7.88
(*) Finding Mean :-
Classmark(Xi):-
(1) (1+4)/2 = 2.5
(2) (4+7)/2=5.5
(3) (7+10)/2= 8.5
(4) (10+13)/2=11.5=A
(5) (13+16)/2 = 14.5
(6) (16+19)/2= 17.5
(*) Di = Xi - A:-
(1) 2.5-11.5=-9
(2) 5.5-11.5=-6
(3) 8.5-11.5=-3
(4) 11.5-11.5=0
(5) 14.5-11.5=3
(6) 17.5-11.5=6
(*) Ui = Di/h or (Xi-A)/h :-
(1) (-9/3) = -3
(2) (-6/3) = -3
(3) (-3/3) = -1
(4) (0/3) = 0
(5) (3/3)=1
(6) (6/3) = 2
(*) fi * Ui :-
(1) 6 * -3 = -18
(2) 30*-2= -60
(3) 40*-1 = -40
(4) 16*0=0
(5) 4*1 =4
(6) 4*2= 8

Assumed mean(A) = 11.5
Class-interval(h) = 4-1=3
𝚺 fi = 100
𝚺 fi Ui = -106
=> 11.5 + 3(-106/100)
=> 11.5 - (306/100)
=> 11.5-3.18
.^. The Mean = 8.32
*********************************
7. The distribution below gives the weights of 30 students of a class. Find the median weight of the students.

sol) Given:- n= 𝝨 Fi = 30
(n/2) = (30/2) = 15
median class = 55-60

L= lower limit of median class=55
h= class-interval= 45-40=5
cf=cumulative frequency of the class before median class=13
f=frequency of the median class=6
=55 + 15-13 *5
6
= 55+ (2/6)*5
=55 + 0.33*5
=55 + 1.66
.^. Median = 56.6
*****************************************
(*) Graphical Representation of Cumulative Frequency Distribution
For drawing ozires, it should be ensured that the class intervals are continuous, because cumulative frequencies are linked with boundaries, but not with limits.
Recall that the values of 10,20,30.....100 are the upper boundaries of the respective class intervals.

To represent the data graphically , we mark the upper boundaries of the class intervals on the horizontal axis(x-axis) and their corresponding cumulative frequencies on the vertical axis(y-axis), choosing a convenient scale.
Now plot the points corresponding to the ordered pairs given by (upper boundary, corresponding cumulative frequency)
i.e., (10,5) (20,8) (30,12) (40,15) (50,18) (60,22)
(70,29) (80,38) (90,45) (100,53)
on a graph paper and join them by a free hand smooth curve. The curve we get is called a cumulative frequency curve, or an ogive (of the less than type)
The term ogive is pronounced as 'ojeev' and is derived from the word ogee.
An ogee is a shape consisting of a concave arc, so forming an S-shaped curve with vertical ends. In architecture , the ogee shape is one of the characteristic of the 14th and 15th century Gothic style.
Again we consider the cumulative frequency distribution and draw its ogive(of the more than type).
recall that, here 0,10,20.....90 are the lower boundaries of the respective class intervals 0-10, 10-20....,,,90-100.
To represent 'the more than type' graphically, we plot the lower boundaries on the X-axis and the corresponding cumulative frequencies on the Y-axis.
Then we plot the points(lower boundaries, corresponding cumulative frequency)
(0,53), (10,48), (20,45), (30,41), (40,38)
(50,35), (60,31), (70,24), (80,15) (90,8),

on a graph paper, and join them by a free hand smooth curve.
The curve we get is a cumulative frequency curve, or an ogive(of the more than type).
*****************************************
(*) Obtaining Median from given curve:
Is it possible to obtain the median from these two cumulative frequency curves. let us see. One obvious way is to locate on
n = 53 = 26.5
2 2
on the y-axis. From this point, draw a line parallel to the x-axis cutting the curve at a point. From this point, draw a perpendicular to the x-axis.
Foot of this perpendicular determines the median of the data.

Another way of obtaining the median :
Draw both ogives (i.e., of the less than type and of the more than type) on the same axis.

The two ogives will intersect each other at a point. From this point, if we draw a perpendicular on the x-axis, the point at which it cuts the x-axis give us the median.
*****************************************
Examples-9. The annual profits earned by 30 shops in a locality give rise to the following distribution :

Draw both ogives for the data above. Hence obtain the median profit.
sol) We first draw the coordinate axes, with lower limits of the profit along the horizontal axis, and the cumulative frequency along the vertical axes.
Then, we plot the points
(5,30)
(10,28)
(15,16)
(20,14)
(25,10)
(30,7) and
(35,3).
We join these points with a smooth curve to get the more than ogive, as shown in the figure below.

Now, let us obtain the classes, their frequencies and the cumulative frequency from the table above.

using these values, we plot the points
(10,2) (15, 14) (20,16) (25,20)
(30,23) (35,27) (40,30)
on the same axes as in the last figure to get the less than ogive, as shown in figure below.
The abcissa of their point of intersection is nearly 17.5, which is the median.
This can also be verified by using the formula. Hence, the median profit(in lakhs) is 17.5 Rs.

Exercise-14.4
1. The following distribution gives the daily income of 50 workers in a factory.

Convert the distribution above to a less than type cumulative frequency distribution, and draw its ogive(a cumulative frequency graph).
Sol) cumulative frequency:-

(*)Less than type cumulative frequency distribution.

(*) ogive(Cumulative freq graph):-

Graph:-

**********************************
2. During the medical check-up of 35 students of a class, their weights were recorded as follows

Draw a less than type ogive for the given data. Hence obtain the median weight from the graph and verify the result by using the formula.
sol) Less than type ogive :-
Weight is plotted in X-axis & No.of students in Y-axis

Given:- Total students is 35
.^. 𝚺Fi = 35
(*) Obtaining median weight from the graph:-
Since 𝚺Fi = 35
So,n= 35
(n/2)= (35/2) = 17.5
We draw a parallel line parallel to x-axis where number of students = 17.5

Where the line intersects it is the median = 46.5
.^. Median = 46.5
(*) Verifying result by using the formulae:-
First converting less than to normal form
Less than:-
(*) Normal Form:-


Median:-
n= 𝚺Fi = 35
n/2 = 35/2 = 17.5
Lower limit of median class(L) =46
Class-interval(h) =40-38=2
Cumulative frequency of the class before median class(cf)=14
Frequency of the median class(F)= 14
Formula:-
=> 46 + 17.5 - 14 *2
14
=> 46+ 3.5 *2
14
=> 46 + (0.25) * 2
=> 46 + 0.5
=> 46.5
Ganesh had recorded the marks of 26 children in his class in mathematics
Summative Assessment-1 in the register as follows.

In the data given in the list above organized? why or why not?
His teacher asked him to report on how his class students had performed in mathematics in their Summative Assessment - 1
Ganesh made the subsequent table to know the performance of his class

In the data given in the above table grouped or ungrouped?
He showed this table to his teacher and the teacher appreciated him for organizing the data to be understood easily.
We can see that most children have got marks between 76-100.
Do you think Ganesh should have used a smaller range? Why or why not?
In the previous class, you had learned about the difference between grouped and ungrouped data as well as how to present this data in the form of tables.
You had also learned to calculate the mean value for ungrouped data. Let us recall this learning and then learn to calculate the mean, median and mode for grouped data.
14.2 Mean of Ungrouped data
As we know the mean (or average) of observations is the sum of the values of all the observations divided by the total number of observations.
Let x1 , x2 ,. . ., xn be observations with respective frequencies f1 , f2 , . . ., fn .
This means that observation x1 occurs f1 times, x2 occurs f2 times, and so on.
Now, the sum of the values of all the observations = f1 x1 + f2 x2 + . . . + fn xn , and the number of observations = f1 + f2 + . . . + fn .
So, the mean x of the data is given by
x = f1 x1 + f2 x2 ..........fn xn
f1 + f2+.........+fn
Recall that we can write this in short, using the Greek letter ∑ which means the summation
i.e., x = ∑ f1x1
∑ f1
*****************************************
Example-1. The marks obtained in mathematics by 30 students of Class X of a certain school are given in the table below. Find the mean of the marks obtained by the students
Solution : Let us re-organize this data and find the sum of all observations.
So,
x = ∑ f1x1
∑ f1
= 1779
30
= 59.3
Therefore, the mean marks are 59.3
In most of our real-life situations, data is usually so large that to make a meaningful study, it needs to be condensed as grouped data. So, we need to convert ungrouped data into grouped data and devise some method to find its mean.
Let us convert the ungrouped data of Example 1 into grouped data by forming class intervals of width, say 15.
Remember that while allocating frequencies to each class-interval, students whose score is equal to in any upper class-boundary would be considered in the next class,
e.g., 4 students who have obtained 40 marks would be considered in the class-interval 40-55 and not in 25-40.
With this convention in our mind, let us form a grouped frequency distribution table.

Now, for each class-interval, we require a point which would serve as the representative of the whole class.
It is assumed that the frequency of each class-interval is centered around its mid-point.
So, the mid-point of each class can be chosen to represent the observations falling in that class and is called the class mark.
Recall that we find the classmark by finding the average of the upper and lower limit of the class.
Classmark -:
= Upper-class limit + Lower class limit
2
For the class 10-25, the classmark is
10+25 = 17.5.
2
Similarly, we can find the class marks of the remaining class intervals. We put them on the table. These class marks serve as our Xi's.
We can now proceed to compute the mean in the same manner as in the previous example.

The sum of the values in the last column gives us Σ f1 x1 .
So, the mean x of the given data is given by
x = ∑ f1x1
∑ f1
= 1860/30
= 62
This new method of finding the mean is known as the Direct Method.
We observe that in the above cases we are using the same data and employing the same formula for calculating the mean but the results obtained are different.
In example (1), 59.3 is the exact mean and 62 is the approximate mean. Can you think why this is so?
Think - Discuss
1. The mean value can be calculated from both ungrouped and grouped data. Which one do you think is more accurate? Why?
2. When it is more convenient to use grouped data for analysis?
Sometimes when the numerical values of x1 and f1 are large, finding the product of x1 and f1 becomes tedious and time-consuming.
So, for such situations, let us think of a method of reducing these calculations.
We can do nothing with the fi's, but we can change each xi to a smaller number so that our calculations become easy.
How do we do this?
What is about subtracting a fixed number from each of these xi 's?
Let us try this method for the data in example1.
The first step is to choose one among the xi 's as the assumed mean, and denote it by 'a'.
Also, to further reduce our calculation work, we may take 'a' to be that xi which lies in the center of x1, x2, ..., xn.
So, we can choose a = 47.5 or a = 62.5. Let us choose a = 47.5.
The second step is to find the deviation of ‘a’ from each of the xi 's, which we denote as di i.e.,
di = xi – a
= xi – 47.5
The third step is to find the product of di with the corresponding fi , and take the sum of all the fi di ’s.
These calculations are shown in the table given below

So, from the above table, the mean of the deviations
d = Σ fi di
Σfi
_ _
Now, let us find the relation between d and x
Since, in obtaining di we subtracted 'a' from
_
each xi so, in order to get the mean x we need
_
to add 'a' to d.
This can be explained mathematically as:
Mean of deviations,
_
d = Σ fi di
Σ fi
So,
_
d = Σ fi(xi-a)
Σ fi
= Σ fi xi - Σ fi*a
Σ fi Σ fi
_
= x - a Σ fi
Σ fi
_ _
d = x - a
Therefore
_
x = a + Σ fi*di
Σ fi
Substituting the values of a, Σfi*di and Σfi from the table, we get
x = 47.5 + 435
30
= 47.5 + 14.5
= 62
Therefore, the mean of the marks obtained by the students is 62.
The method discussed above is called the Assumed Mean Method.
Observe that in the table given below the values in Column 4 are all multiples of 15.
So, if we divide all the values of Column 4 by 15, we would get smaller numbers which we then multiply with fi.
(Here, 15 is the class size of each class interval).
So, let
ui = xi - a
h
where a is the assumed mean and h is the class size.
Now, we calculate ui in this way and continue as before (i.e., find di*ui and then Σfi*ui).
Taking h = 15.
[ Generally size of the class is taken as h but it need not be size of the class always]
_
Let u = Σ fi*ui
Σ fi

_
Here , again let us find the relation between u
_
and x
We have
ui = xi - a
h
So
_
u = Σ fi*ui
Σ fi
So
_
u = Σ fi( xi - a)
h
---------------
Σfi
= 1 [ Σ fi*xi - Σ fi*a]
h Σ fi Σ fi
_
= 1 ( x - a)
h
or
_ _
h* u = x - a
_ _
x = a + h*u
Therefore,
_
x = a + h[ Σ fi*ui ]
Σ fi
or
_
x = a + (Σ fi*ui) * h
Σ fi
Substituting the values of a, Σ fi*ui and Σ fi from the table.
we get
_
x = 47.5 + 15 *(29/30)
= 47.5 + 14.5
= 62
So, the mean marks obtained by a student are 62.
The method discussed above is called the
Step-deviation method.
We note that :
*) The step-deviation method will be convenient to apply if all the di's have a common factor.
*) The mean obtained by all the three methods is the same.
*) The assumed mean method and step-deviation method are just simplified forms of the direct method.
_ _
*) The formula x = a + h*u still holds if a and h are not as given above, but are any non-zero numbers such that
ui = xi - a
h
*****************************************
Example-2. The table below gives the percentage distribution of female teachers in the primary schools of rural areas of various states and union territories(U.T) of India. Find the mean percentage of female teachers using all the three methods.

sol) Let us find the class marks xi of each class, and put them in a table
Here we take a = 50, h=10,
then di = xi - 50 and
ui = xi - 50
10
we now find di and ui and put them in the table

From the table above, we obtain
Σ fi = 35,
Σ fi*xi = 1390
Σ fi*di = -360
Σ fi*ui = -36
Using the direct method
_
x = Σ fi*xi
Σ fi
= 1390
35
= 39.71
(*) Using the assumed mean method
_
x = a + Σ fi*di
Σ fi
= 50 + (-360)
35
= 50 - 10.29 = 39.71
(*) Using the step-deviation method
_
x = a + [Σ fi*ui ] * h
Σ fi
= 50 + (-36) * 10
35
= 39.71
Therefore, the mean percentage of female teachers in the primary schools of rural areas is 39.71
Even if the class sizes are unequal, and xi are large numerically, we can still apply the step-deviation method by taking h to be a suitable divisor of all the di's
*****************************************
Example-3. The distribution below shows the number of wickets taken by bowlers in one-day cricket matches. Find the mean number of wickets by choosing a suitable method. What does the mean signify?

sol) Here, the class size varies, and the xi's are large.
Let us still apply the step-deviation method with
a= 200 and
h = 20.
Then, we obtain the data as given in the table.

So
_
x = a + (Σ fi*ui) * h
Σ fi
= 200 + (-106) * 20
45
= 200 - 47.11
= 152.89
Thus, the average number of wickets taken by these 45 bowlers in one-day cricket is 152.89
****************************************
Exercise-14.1
1) A survey was conducted by a group of students as a part of their environment awareness program, in which they collected the following data regarding the number of plants in 20 houses in a locality. Find the mean number of plants per house.

Sol) It is assumed that the frequency
around its mid-point. So, the mid-point
observations falling therein class and is named the category mark.
Recall that we find the classmark by findingthe type of the upper and lower limit of the category .
Recall that we find the classmark by finding
Classmark = Upper-class limit + Lower class limit Classmark
2
For class 0 - 2,
the classmark is
0+2 =1
2
Similarly, we will find the classmarks of the remaining class intervals. We put them on the table. These class marks serve as our xi's. we will now proceed to compute the mean

Mean( x ) = ∑ f1x1 /∑ f1
= 162/20
= 8.1
2
For class 0 - 2,
the classmark is
0+2 =1
2
Similarly, we will find the classmarks of the remaining class intervals. We put them on the table. These class marks serve as our xi's. we will now proceed to compute the mean
Mean( x ) = ∑ f1x1 /∑ f1
= 162/20
= 8.1
Mean no. of plants are = 8.1
This new method of finding the mean is known as the Direct Method
******************************************************
2. Consider the following distribution of daily wages of 50 workers in a factory.

Sol) we have

Where Assumed mean (A) = 325
h = class interval = 250-200 = 50

(*) Mean
=
= 325 + 50* (-12/50)
= 325 +[ -12]
= 325 - 12
= 313
The method above is named the Step-deviation method.
Note that:-
(*) The step-deviation method will be convenient to apply if all the di's have a common factor.
in the above table, the di's value have the same factor '50'
-100/50 = - 20
-50/50 = -1
50/50=1
100/50 = 2
(*) The assumed mean method and step-deviation method are just simplified sorts of the
direct method.
******************************************************
3. The following distribution shows the daily pocket allowance of youngsters of a neighborhood. The mean pocket allowance is 18. Find the missing frequency f.

sol)


18 = (752 + 20f)
44 + f
792 + 18f = 752 + 20f
2f = 40
f = 20
*********************************************************

sol)

Assumed mean(A) = 75.5
class interval(h) = 68-65 = 3
Xi = (Upper + Lower class)
2
= (65 + 68)
2
= 66.5
Di = Xi - A = 66.5 - 75.5 = -9
Ui = Xi - a / h = ( 66.5 - 75.5) / 3 = -9/3 = -3
Fi Ui =( 2 * -3) = -6
Σ Fi= 30
Σ Fi Ui = 4
(*) Mean-:
= 75.5 + 3 * (4/30)
= 75.5 + 0.4
= 75.9
Therefore, the mean heartbeats per minutes of women are = 75.9
**************************************************************
5. In a retail market, fruit vendors were commercialism oranges unbroken in packing baskets. These baskets contained varied numbers of oranges. the subsequent was the distribution of
oranges.

find the mean number of oranges kept in each basket. Which method of finding the mean did you choose?
sol)

Assumed mean (A) = 22
Class interval(h) = 15 - 10 = 5
𝚺 Fi = 400
𝚺 Fi Ui = 25
(*) Mean:-
We apply step-deviation method as all Di's have common factor "5" and also Xi and Fi are numerically large numbers
= 22 + 5 [25/400]
= 22 + 5(1/16)
= 22 + 5/16
= 22 + 0.31
Therefore, Mean = 22.31
***************************************************************
6. The table below shows the daily expenditure on the food of 25 households in a locality.

Find the mean daily expenditure on food by a suitable method.
sol) (*) Classmark (Xi):-
(1) (100 + 150) / 2 = 125
so on...
(5) (300 + 350) / 2 = 325
(*) Di = Xi - A
(1) Di = 125 - 225 = -100
so on...
(5) Di = 325 - 225 = 100
(*) Ui = (Xi - A) / h
(1) (125 - 225) / 50 = (-100)/50 = -2
so on...
(5) (325 - 225) / 50 = (100) / 50 = 2
(*) Fi Ui:-
(1) 4 * (-2) = -8
so on...
(5) 2 * 2 = 4

Assumed mean (A) = 225
Class interval (h) = 150 - 100 = 50
𝚺 Fi = 25
𝚺 Fi Ui = -7
(*) Mean:-
= 225 + 50 *(-7/25)
= 225 + 2 * (-7)
= 225 - 14
Mean (x)= 211 rs is the daily expenditure on food
***********************************************
7. To find out the concentration of SO2 in the air (in parts per million, i.e., ppm), the data was collected for 30 localities in a certain city and is presented below:

Find the mean concentration of SO2 in the air.
Sol) Classmark (Xi) :-
(1) (0.00 + 0.04) / 2
= 0.02
so on...
(5) ( 0.16 + 0.20) / 2
= 0.22
(*) Fi Xi :-
(1) 4 * 0.02 = 0.08
So on...
(5) 2 * 0.20 = 0.44

(*) Mean:-
X = 2.96 / 30
remove a decimal point from 2.96 and transfer it to the denominator
X = 296 / 3000 divide by "3" we get,
=> 98.67 / 1000
Transfer 1000 to numerator we get
=> 0. 09867 or 0.099
Mean concentration of SO2 in the air is = 0.099 ppm
We used this method as Fi and Xi is easier to calculate and sum
********************************************************
8. A class teacher has the following attendance record of 40 students of a class for the whole term. Find the mean number of days a student was present out of 56 days in the term.
sol)
(*) Classmark(Xi)-:
(1) Xi = (35 +38) / 2 = 36.5
so on...
(7) Xi = (53+56)/2 = 54.5
(*) Xi Fi :-
(1) 36.5 * 1 = 36.5
so on...
(7) 54.5 *11 = 599.5

= 1961 / 40
= 49.025 or 49
Thus, the mean no.of days a student was present is 49.
OPtional :-
We will use a direct method as the class interval is not the same

= > 499 / 40
=> 12.48 is the mean number of days a student was absent
*********************************************************
9. The following table gives the literacy rate (in percentage) of 35 cities. Find the mean literacy rate.

Sol) ClassMark (Xi):-
(1) (45 + 55) / 2 = 50
so on...
(5) (85+75) / 2 = 90
Assumed mean(A) = 70
Class interval(h) = 55 - 45 = 10
(*) Di = Xi - A
(1) 50 - 70 = -20
so on...
(5) 90-70 = 20
(*) Ui = (Xi - A)/h
(1) -20 / 10 = -2
so on...
(5) 20/10 = 2
(*) Fi * Ui
(1) 3 * -2 = -6
so on...
(5) 3 *2 = 6

𝚺 Fi = 35
𝚺 Fi Ui = -2
=> 70 + 10[ -2 / 35]
=> 70 + [-20/35]
=> 70 + [-4/7]
=> 70 - 0.57
=> 69.43 is the Mean literacy rate
****************************************
(*) Mode
A mode is that value among observations which occur most frequently.
Before learning about calculating the mode of grouped data let us first recall how we found the mode for ungrouped data through the following example
Example-4. The wickets taken by a bowler in 10 cricket matches are as follows : 2,6,4,5,0,2,1,3,2,3.
Find the mode of the data.
sol) let us arrange the observations in order i.e.,
0,1,2,2,2,3,3,4,5,6
Clearly, 2 is the number of wickets taken by the bowler in the maximum number of matches(i.e., 3 times). So, the mode of this data is 2.
In a grouped frequency distribution, it is not possible to determine the mode by looking at the frequencies.
Here, we can only locate a class with the maximum frequency, called the modal class.
The mode is a value inside the modal class, and is given by the formula.

******************************************
Example-5 : A survey conducted on 20 households in a locality by a group of students resulted in the following frequency table for the number of family members in a household.

Find the mode of this data
sol) Here the maximum class frequency is 8, and the class corresponding to this frequency is 3-5.
So, the modal class is 3-5.
Now,
modal class = 3-5,
boundary limit(L) of modal class = 3
class size(h) = 2
frequency of the modal class(f1) = 8
frequency of class preceding the modal class(f0) = 7
frequency of class succeeding the modal class (f2) = 2.
Now , let us substitute these values in the formula
= 3 + ( 8 - 7 ) * 2
(2*8) - 7 - 2
= 3 + 2 = 3.286
7
Therefore, the mode of the data is 3.286
*****************************************
Example-6 . The marks distribution of 30 students in a mathematics examination are given in the adjacent table.
Find the mode of this data. Also compare and interpret the mode and the mean.

sol). Since the maximum number of students (i.e., 7) have got marks in the interval,40-55
the modal class is 40 - 55
The lower boundary(L) of the modal class = 40.
The class size(h) = 15.
The frequency of modal class(f1) = 7
The frequency of the class preceding the modal class(f0) = 3.
The frequency of the class succeeding the modal class (f2) = 6.
Now , using the formula :
= 40 + ( 7 - 3 ) * 15
(2*7) - 6 - 3
= 40 + 12 = 52
Interpretation : The mode marks is 52.
Now, from example 1, we know that the mean marks is 62.
So, the maximum number of students obtained 52 marks, while on an average a student obtained 62 marks.
*****************************************
Exercise-14.2
1. The following table shows the ages of the patients admitted to a hospital for a year:

Find the mode and the mean of the data given above. Compare and interpret the two measures of central tendency.
sol) Class Mark:-
(1) 5+15 / 2 = 10
(2) 15 +25 / 2 = 20
(3) 25+35 / 2 = 30
(4) 35+45/2 = 40
(5) 45 + 55/2 = 50
(6) 55 +65 / 2 = 60
(*) Fi * Xi:-
(1) 6 * 10 = 60
(2) 11 * 20 = 220
(3) 21 * 30 = 630
(4) 23 * 40 = 920
(5) 14 * 50 = 700
(6) 5 * 60 = 300

=> 2830 / 80
Mean(X) = 35.375
(*) Mode:-


Modal class
= Interval with higher frequency
= 35 -45
Where L = Lower limit of modal class = 35
h = class-interval = 15-5=10
F1 = frequency of the modal class = 23
F. = frequency of the class before modal class = 21
F2 = frequency of the class after modal class = 14
Mode = 35 + 23-21 * 10
2(23) -21-14
= 35 + 2 * 10
46-35
= 35 + (2/11) * 10
= 35 + 1.8
Mode = 36.8
***************************************************
2. The following data gives the information on the observed lifetimes (in hours) of 225 electrical components :

Determine the modal lifetimes of the components.
sol) Modal class = Interval with the highest frequency = 60-80
h = class-interval = 20-0 = 20
L= lower limit of modal class = 60
F1=frequency of the modal class = 61
F.=frequency of the class before modal class = 52
F2=frequency of the class after modal class = 38


Mode = 60 + 61-52 *20
2(61)-52-38
= 60 + 9 *2
122 - 90
= 60 + (9/
= 60 + (9/8) * 5
= 60 + (45/8)
=60 + 5.62
Mode = 65.62
********************************
3. The following data gives the distribution of total monthly household expenditure of 200 families of a village. Find the modal monthly expenditure of the families. Also, find the mean monthly expenditure :

Sol)

Modal class = Interval with the highest frequency = 1500-2000
h = class-interval = 1500-1000 = 1500
L= lower limit of modal class = 1500
F1=frequency of the modal class = 40
F.=frequency of the class before modal class = 24
F2=frequency of the class after modal class = 33
Mode = 1500 + 40-24 *500
2(40)-24-33
=> 1500 + 16 *500
80-57
=> 1500 + (16/23) * 500
=> 1500 + 347.826
=> 1847.83.
Therefore, the modal monthly expenditure of families is Rs.1847.83
Now, Mean:-
Classmark(Xi) :-
(1) (1000+1500)/2 = 1250
(2) (1500+2000)/2 = 1750
(3) (2000+2500)/2 = 2250
(4) (2500+3000)/2 = 2750
(5) (3000+3500)/2 = 3250 =A
(6) (3500+4000)/2 = 3750
(7) (4000+4500)/2 = 4250
(8) (4500+5000)/2 = 4750
(*) Di = Xi - A
(1) 1250 - 3250 = -2000
(2) 1750-3250= -1500
(3) 2250-3250= -1000
(4) 2750-3250= -500
(5) 3250-3250=0
(6) 3750-3250= 500
(7) 4250-3250=1000
(8) 4750-3250=1500
(*) Ui = Di /h or (Xi-3250)/500
(1) -2000/500 = -4
(2) -1500/500= -3
(3) -1000/500= -2
(4) -500/500=1
(5) 0/500 = 0
(6) 500/500 = 1
(7) 1000/500=2
(8) 1500/500=3
(*) Fi * Ui:-
(1) 24 * -4 = -96
(2) 40 * -3 = -120
(3) 33 * -2 = -66
(4) 28 * -1= -28
(5) 30 * 0 = 0
(6) 22 *1 = 22
(7) 16 * 2 = 32
(8) 7 *3 = 21

𝚺 Fi = 200
𝚺 Fi Ui = 235
Assumed mean(A) = 3250
Class interval(h) = 1500-1000=500
(*) Mean:-
=> 3250 + 5
=> 3250 + 5 *( -235/2)
=> 3250 - (1175/2)
=> 3250 - 587.5
=> 2662.5
.^. Mean expenditure =2662.5
*******************************************************
4). The following distribution gives the state-wise, teacher-student ratio in higher secondary schools of India. Find the mode and mean of this data. Interpret the two measures.
Sol) Class interval(h) = 20-15 = 5

(*) Modal class = interval with highest frequency = 30-35
L = Lower limit of modal class =30
F1 =frequency of modal class = 10
F. = frequency of class before modal class = 9
F2 = frequency of class after modal class = 3
= 30 + 10-9 * 5
2(10)-9-3
= 30 + 1 *5
20-12
=30 + (5/8)
= 30 + 0.625
Mode = 30.625
(!!) Mean:-
(*) Class mark (Xi):-
(1) (15+20)/2 = 17.5
(2) (20+25)/2 = 22.5
(3) (25+30)/2= 27.5
(4) (30+35)/2= 32.5
(5) (35+40)/2= 37.5
(6) (40+45)/2= 42.5
(7) (45+50)/2= 47.5
(8) (50+55)/2= 52.5
(*) Di = Xi - A or Xi - 37.5
(1) 17.5-37.5 = -20
(2) 22.5-37.5 = -15
(3) 27.5-37.5= -10
(4) 32.5-37.5= -5
(5) 37.5 - 37.5 = 0
(6) 42.5 - 37.5= 5
(7) 47.5- 37.5 = 10
(8) 52.5 - 37.5 = 15
(*) Ui = (Xi-A)/h or (Di/h)
(1) -20/5 = -4
(2) -15/5= -3
(3) -10/5 = -2
(4) -5/5 = -1
(5) 0/5 = 0
(6) 5/5 = 1
(7) 10/5 = 2
(8) 15/3 = 3
(*) Fi * Ui
(1) 3*-4 = -12
(2) 8 *-3 = -24
(3) 9*-2 = -18
(4) 10*-1 = -10
(5) 3*0=0
(6) 0*1=0
(7) 0*2=0
(8) 2*3=6

(*) Mean :-
Class interval(h) = 20-15 = 5
Assumed mean(A)= 37.5
𝚺 Fi = 35
𝚺 Fi * Ui = -58
=> 37.5 +
=> 37.5 - (58/7)
=> 37.5 - 8.286
.^. Mean (X)= 29.214
Student-teacher ratio=Mode=30.625
Student-teacher ratio=Mean=29.214
********************************
5. The given distribution shows the number of runs scored by some top batsmen of the world in one-day international cricket matches.

sol) Modal class= interval with highest frequency= 4000-5000

L = lower limit of modal class = 4000
Class interval(h) = 4000-3000=1000
F1 = Frequency of the modal class = 18
F. = frequency of class before modal class = 4
F2=frequency of class after modal class=9
=> 4000 + 18-4 *1000
2(18)-4-9
=> 4000 + 14 *1000
36-13
=> 4000+14000
23
=> 4000+ 608.69
.^.Mode= 4608.69
**********************************
6. A student noted the number of cars passing through a spot on a road for 100 periods, each of 3 minutes, and summarized this in the table given below.

Find the mode of the data.
sol) Modal class= interval with highest frequency = 40-50.

L=Lower limit of modal class=40
Class interval(h)=10-0=10
Frequency of modal class(F1) = 20
Frequency of class before modal class(F.) = 12
Frequency of class after modal class(F2) = 11
=> 40 + 20-12 *10
2(20)-12-11
=> 40 + 8 *10
40-23
=> 40 + (80/17)
=> 40 + 4.7
.^. Mode = 44.7
******************************************
(*) Median of Grouped data
Median is a measure of central tendency which gives the value of the middle-most observation in the data.
Recall that for finding the median of un-grouped data. we first arrange the data values or the observation in ascending order.
Then, if n is odd, the median is the
(n + 1)th observation and
2
If n is even, then the median will be the average of the
(n)th and ( n + 1)th observations.
2 2
Suppose, we have to find the median of the following data, which is about the marks, out of 50 obtained by 100 students in a test :

First, we arrange the marks in ascending order and prepare a frequency table as follows :

Here n = 100, which is even. The median will be the average of the
(n )th and the
2
(n + 1)th
2
observations, i.e., the 50th and 51th observations. To find the position of these middle values, we construct cumulative frequency.

Now we add another column depicting this information to the frequency table above and name it as cumulative frequency column.
From the table above, we see that :
50 th observation is 28
51 th observation is 29
median = 28 +29 = 28.5
2
Remark : Column 1 and column 3 in the above table are known as Cumulative Frequency Table.
The median marks 28.5 conveys the information that about 50% students obtained marks less than 28.5 and another 50% students obtained marks more than 28.5
Consider a grouped frequency distribution of marks obtained, out of 100, by 53 students, in a certain examination, as shown in adjacent table.

From the table, try to answer the following questions:
How many students have scored marks less than 10? The answer is clearly 5.
How many students have scored less than 20 marks?
Observe that the number of students who have scored less than 20 include the number of students who have scored marks from 0-10 as well as the number of students who have scored marks from 10-20.

So the total number of students with marks less than 20 is 5+3, i.e., 8.
We say that the cumulative frequency of the class 10-20 is 8.
Similarly, we can compute the cumulative frequencies of the other classes, i.e., the number of students with marks less than 30, less than 40,...., less than 100.
This distribution is called the cumulative frequency distribution of the less than type.
Here 10,20,30.....100, are the upper boundaries of the respective class intervals.
We can similarly mark the table for the number of students with scores more than or equal to 0(this number is same as sum of all the frequencies), more than above sum minus the frequency of the first class interval),
more than or equal to 20 ( this number is same as the sum of all frequencies minus the sum of the frequencies of the first two class intervals), and so on.
We observe that all 53 students have scored marks more than or equal to 0.

Since there are 5 students scoring marks in the interval 0-10, this means that there are 53-5=48 students getting more than or equal to 10 marks.
Continuing in the same manner, we get the number of students
scoring 20 or above as 48-3 =45
or above as
45-4 = 41, and so on,as shown in the table.
This table above is called a cumulative frequency distribution of the more than type.
Here 0,10,20...,90 give the lower boundaries of the respective class intervals.
Now, to find the median of grouped data, we can use of any of these cumulative frequency distributions.
Now in a grouped data, we may not be able to find the middle observation by looking at the cumulative frequencies as the middle observation will be some value in a class interval.
It is, therefore, necessary to find the value inside a class that divides the whole distribution into two halves. But which class should this be?
To find this class, we find the cumulative frequencies of all the classes and (n/2).
We know locate the class whose cumulative frequency (n/2) for the first time.

This is called the median class.
In the distribution above,
n = 53.
n = 26.5
2
Now 60-70 is the class whose cumulative frequency 29 is greater than (and nearest to)
n , i.e., 26.5
2
Therefore, 60-70 is the median class.
After finding the median class, we use the following formula for calculating the median.

Substituting the values
n = 26.5
2
L = 60
cf = 22
f = 7
h = 10
In the formula above, we get
Median = 60 + [ 26.5 - 22 ] * 10
6
= 60 + 45
7
= 66.4
So, about half the students have scored marks less than 66.4, and the other half have scored marks more than 66.4
******************************************
Example-7. A survey regarding the heights(in cm) of 51 girls of Class X of a school was conducted and data was obtained as shown in table. Find their medium.

sol) To calculate the median height, we need to find the class intervals and their corresponding frequencies.
The given distribution being of the less than type, 140,145,150.....165 give the upper limits of the corresponding class intervals.

So, the classes should be below
140,
140-145
145-150.........
160-165
Observe that from the given distribution, we find that there are 4 girls with height less than 140, i.e., the frequency of class interval below 140 is 4.
Now, there are 11 girls with heights less than 155 and 4 girls with height less than 140.
Therefore, the number of girls with height in the interval
140-145 is 11-4=7.
Similarly, the frequencies can be calculated as shown in table.
Number of observations,
n = 51
n = 51 = 25.5 th observation, which lies in the
2 2
class 145-150.
.^. 145-150 is median class
Then, L(the lower boundary) = 145,
cf(the cumulative frequency of the class preceding 145-150) = 11
f(the frequency of the median class 145-150) = 18,
h(the class size) = 5.
= 145 + (25.5 - 11) * 5
18
= 145 + 72.5
18
= 149.03
So, the median height of the girls is 149.03 cm.
This means that the height of about 50% of the girls is less than this height, and that of other 50% is greater than this height.
*****************************************
Example-8. The median of the following data is 525. Find the values of x and y, if the total frequency is 100. here, CI stands for class interval and Fr for frequency.

sol) It is given that n = 100
So, 76+x+y=100,
i.e., x + y = 24 ----(1)
The median is 525, which lies in the class 500-600
So,
L=500
f = 20
cf = 36 + x
h = 100
Using the formula
2
L = 60
cf = 22
f = 7
h = 10
In the formula above, we get
Median = 60 + [ 26.5 - 22 ] * 10
6
= 60 + 45
7
= 66.4
So, about half the students have scored marks less than 66.4, and the other half have scored marks more than 66.4
******************************************
Example-7. A survey regarding the heights(in cm) of 51 girls of Class X of a school was conducted and data was obtained as shown in table. Find their medium.

sol) To calculate the median height, we need to find the class intervals and their corresponding frequencies.
The given distribution being of the less than type, 140,145,150.....165 give the upper limits of the corresponding class intervals.

So, the classes should be below
140,
140-145
145-150.........
160-165
Observe that from the given distribution, we find that there are 4 girls with height less than 140, i.e., the frequency of class interval below 140 is 4.
Now, there are 11 girls with heights less than 155 and 4 girls with height less than 140.
Therefore, the number of girls with height in the interval
140-145 is 11-4=7.
Similarly, the frequencies can be calculated as shown in table.
Number of observations,
n = 51
n = 51 = 25.5 th observation, which lies in the
2 2
class 145-150.
.^. 145-150 is median class
Then, L(the lower boundary) = 145,
cf(the cumulative frequency of the class preceding 145-150) = 11
f(the frequency of the median class 145-150) = 18,
h(the class size) = 5.
= 145 + (25.5 - 11) * 5
18
= 145 + 72.5
18
= 149.03
So, the median height of the girls is 149.03 cm.
This means that the height of about 50% of the girls is less than this height, and that of other 50% is greater than this height.
*****************************************
Example-8. The median of the following data is 525. Find the values of x and y, if the total frequency is 100. here, CI stands for class interval and Fr for frequency.

sol) It is given that n = 100
So, 76+x+y=100,
i.e., x + y = 24 ----(1)
The median is 525, which lies in the class 500-600
So,
L=500
f = 20
cf = 36 + x
h = 100
Using the formula
525 = 500 + (50-36-x) * 100
20
525 - 500 = (14-x)*5
25 = 70-5x
5x = 70-25 = 45
x = 9
Therefore, from (1),
we get 9 + y = 24
i.e., y = 15

Note : The median of grouped data with unequal class sizes can also be calculated.
*****************************************
Exercise-14.3
1. The following frequency distribution gives the monthly consumption of electricity of 68 consumers of a locality. Find the median, mean and mode of the data and compare them.

sol) Assumed mean(A) = 135
Class-interval(h) = 85-65 = 20
(*) Mean:-
(*) Classmark(Xi):-
(1) (65+85)/2 = 75
(2) ( 85+105)/2= 95
(3) (105+125)/2 = 115
(4) (125+145)/2= 135=A
(5) (145+165)/2 = 155
(6) (165+185)/2 = 175
(7) ( 185+205)/2 = 195
(*) Di= Xi-A (OR) Xi-135
(1) 75-135=-60
(2) 95-135=-40
(3) 115-135= -20
(4) 135-135=0
(5) 155-135=20
(6) 175-135=40
(7) 195-135=60
(*) Ui = Di/h (or) (Xi-A)/h (or) (Xi-135)/20
(1) -60/20 = -3
(2) -40/20 = -2
(3) -20/20 = -1
(4) 0/20 = 0
(5) 20/20 = 1
(6) 40/20 = 2
(7) 60/20 = 3
(*) fi*Ui:-
(1) 4*-3 = -12
(2) 5*-2 = -10
(3) 13*-1 = -13
(4) 20*0=0
(5) 14*1 = 14
(6) 8*2 = 16
(7) 4*3 = 12

𝚺fi = 68
𝚺 fi*Ui = 7
=> 135 + 20 *(7/68)
=> 135 + 2.05
.^. Mean = 137.05
(2) Median:-
n= 𝚺f1 = 68
n/2 = 68/2 = 34

Median class= 125-145
lower limit of median class(L)=125
class-interval(h) = 85-65=20
cumulative frequency of the class before median class(cf) = 22
frequency of the median class(f)=20

=125+34-22*20
20
= 125+(12/20) * 20
= 125+ 12
.^. median = 137
(*)Mode :-

modal class=interval with highest frequency = 125-145
lower limit of modal class(L)=125
class-interval(h) = 85-65=20
frequency of the modal class(f1)=20
frequency of class before modal class(f0)=13
frequency of class after modal class(f2) = 14
=125 +34-22*20
20
=125+(12/
=125+12
.^. Mode = 137
********************************************
2. If the median of 60 observations, given below is 28.5, find the values of x and y.

sol) Given Median = 28.5
so, 20-30 is the median class
(*) Given :- median of 60 observation
so, n= 𝚺fi=60
n/2= (60/2) = 30

lower limit of median class(L)= 20
class-interval(h) = 10-0=10
cumulative frequency of the class before median class(cf) = 5+x
frequency of the median class = 20
28.5 = 20 +30-(5+x)*10
20
28.5 = 20 + 25-x *
28.5 = 20 +(25-x)
2
28.5 - 20 = (25-x) / 2
8.5 * 2 = 25-x
17 = 25-x
x = 25-17
.^. x = 8 --------(1)
Also,

𝚺fi = 5+x+20+15+y+5
60 = 45 + x +y
substitute (1) x = 8
60 = 45+8+y
60-53=y
7=y ------(2)
Hence , X= 8, y = 7
*********************************************
3. A life insurance agent found the following data about the distribution of ages of 100
policy holders. Calculate the median age.
[Policies are given only to persons having age 18 years onwards but less than 60 years.]

sol) Given = n = 𝚺fi =100
n/2 = (100/2) = 50
(*) Normal Form:-

.^. Median class = 35-40

lower limit of median class(L)= 35
Class-interval(h) = 25-20=5
cumulative frequency of the class before median class(cf) = 45
frequency of the median class(f) = 33
= 35 +50-45*5
33
= 35 +(5/33) * 5
= 35 + 0.76
Median = 35.76
***********************************
4. The lengths of 40 leaves of a plant are measured correct to the nearest millimeter, and the data obtained is represented in the following table :

Find the median length of the leaves. (Hint-: The data needs to be converted to continuous classes for finding the median since the formula assumes continuous classes. The classes then change to 117.5 - 126.5, 126.5 - 135.5, ..., 171.5 - 180.5.)
sol) Given:- n = 𝚺 fi = 40
(n/2) = (40/2) =20
(*) Dis-continuous
Observe that class interval
=> 118-126 and 127-135 is discontinuous
We can see the difference is 127-126=1
so, Diff/2 = 1/2 = 0.5
.^. we add 0.5 to each upper-limit and subtract 0.5 from lower-limit to make the class interval continuous. the frequency will remain same.
(*) Continuous :-

Median= 144.5-153.5
lower limit of median class(L)= 144.5
class-interval(h) = 126.5-117.5= 9
cumulative frequency of the class before median class(cf)=17
frequency of the median class(f) = 12
= 144.5 + 20-17 *9
12
= 144.5 + (3/12)*9
= 144.5 + 2.25
.^. median = 146.75
************************************
5. The following table gives the distribution of the life-time of 400 neon lamps

Find the median lifetime of a lamp.
sol) Given:- n = 𝚺 fi = 400
(n/2) = (400/2) = 200
Median class= 3000-3500

Lower limit of median class(L) = 3000
class-interval(h) = 2000-1500=500
cumulative frequency of the class before median class(cf) = 130
frequency of the median class(f) = 86
=3000 + 200-130 *500
86
= 3000 +(70/86) * 500
= 3000 + (0.81) * 500
= 3000 + 406.97
.^. Median life of lamp = 3406.97hrs
*************************************
6. 100 surnames were randomly picked up from a local telephone directory and the frequency distribution of the number of letters in the English alphabet in the surnames was obtained as follows

Determine the median no of letters in the surnames. Find the mean no of letters in the surnames? Also, find the modal size of the surnames.
Sol) Given:- n = 𝞢 Fi = 100
(n/2) = 100/2 = 50
.^. 7-10 is the median class

Lower limit of median class(L) = 7
Class-interval(h) = 4-1=3
cumulative frequency of the class before median class(CF) = 36
Frequency of the median class(F) = 40
=> 7 +50-36*3
40
=> 7+ (14/40) *3
=> 7+ (0.35)*3
=> 7+ 1.05
.^. Median = 8.05
(*) Finding Mode:-

Modal class= interval with highest frequency= 7-10
Class-interval(h) = 4-1=3
frequency of the modal class(f1)=40
frequency of class before modal class(f.) = 30
frequency of class after modal class(f2) = 16

=7 + 40-30 *3
2(40)-30-16
=> 7 + 10 *3
80-46
=> 7+ (10/34) *3
=> 7+ (0.29)*3
=> 7+ 0.88
.^. Mode = 7.88
(*) Finding Mean :-
Classmark(Xi):-
(1) (1+4)/2 = 2.5
(2) (4+7)/2=5.5
(3) (7+10)/2= 8.5
(4) (10+13)/2=11.5=A
(5) (13+16)/2 = 14.5
(6) (16+19)/2= 17.5
(*) Di = Xi - A:-
(1) 2.5-11.5=-9
(2) 5.5-11.5=-6
(3) 8.5-11.5=-3
(4) 11.5-11.5=0
(5) 14.5-11.5=3
(6) 17.5-11.5=6
(*) Ui = Di/h or (Xi-A)/h :-
(1) (-9/3) = -3
(2) (-6/3) = -3
(3) (-3/3) = -1
(4) (0/3) = 0
(5) (3/3)=1
(6) (6/3) = 2
(*) fi * Ui :-
(1) 6 * -3 = -18
(2) 30*-2= -60
(3) 40*-1 = -40
(4) 16*0=0
(5) 4*1 =4
(6) 4*2= 8

Assumed mean(A) = 11.5
Class-interval(h) = 4-1=3
𝚺 fi = 100
𝚺 fi Ui = -106
=> 11.5 + 3(-106/100)
=> 11.5 - (306/100)
=> 11.5-3.18
.^. The Mean = 8.32
*********************************
7. The distribution below gives the weights of 30 students of a class. Find the median weight of the students.

sol) Given:- n= 𝝨 Fi = 30
(n/2) = (30/2) = 15
median class = 55-60

L= lower limit of median class=55
h= class-interval= 45-40=5
cf=cumulative frequency of the class before median class=13
f=frequency of the median class=6
=55 + 15-13 *5
6
= 55+ (2/6)*5
=55 + 0.33*5
=55 + 1.66
.^. Median = 56.6
*****************************************
(*) Graphical Representation of Cumulative Frequency Distribution
For drawing ozires, it should be ensured that the class intervals are continuous, because cumulative frequencies are linked with boundaries, but not with limits.
Recall that the values of 10,20,30.....100 are the upper boundaries of the respective class intervals.

To represent the data graphically , we mark the upper boundaries of the class intervals on the horizontal axis(x-axis) and their corresponding cumulative frequencies on the vertical axis(y-axis), choosing a convenient scale.
Now plot the points corresponding to the ordered pairs given by (upper boundary, corresponding cumulative frequency)
i.e., (10,5) (20,8) (30,12) (40,15) (50,18) (60,22)
(70,29) (80,38) (90,45) (100,53)
on a graph paper and join them by a free hand smooth curve. The curve we get is called a cumulative frequency curve, or an ogive (of the less than type)
The term ogive is pronounced as 'ojeev' and is derived from the word ogee.
An ogee is a shape consisting of a concave arc, so forming an S-shaped curve with vertical ends. In architecture , the ogee shape is one of the characteristic of the 14th and 15th century Gothic style.
Again we consider the cumulative frequency distribution and draw its ogive(of the more than type).
recall that, here 0,10,20.....90 are the lower boundaries of the respective class intervals 0-10, 10-20....,,,90-100.
To represent 'the more than type' graphically, we plot the lower boundaries on the X-axis and the corresponding cumulative frequencies on the Y-axis.
Then we plot the points(lower boundaries, corresponding cumulative frequency)
(0,53), (10,48), (20,45), (30,41), (40,38)
(50,35), (60,31), (70,24), (80,15) (90,8),

on a graph paper, and join them by a free hand smooth curve.
The curve we get is a cumulative frequency curve, or an ogive(of the more than type).
*****************************************
(*) Obtaining Median from given curve:
Is it possible to obtain the median from these two cumulative frequency curves. let us see. One obvious way is to locate on
n = 53 = 26.5
2 2
on the y-axis. From this point, draw a line parallel to the x-axis cutting the curve at a point. From this point, draw a perpendicular to the x-axis.
Foot of this perpendicular determines the median of the data.

Another way of obtaining the median :
Draw both ogives (i.e., of the less than type and of the more than type) on the same axis.

The two ogives will intersect each other at a point. From this point, if we draw a perpendicular on the x-axis, the point at which it cuts the x-axis give us the median.
*****************************************
Examples-9. The annual profits earned by 30 shops in a locality give rise to the following distribution :

Draw both ogives for the data above. Hence obtain the median profit.
sol) We first draw the coordinate axes, with lower limits of the profit along the horizontal axis, and the cumulative frequency along the vertical axes.
Then, we plot the points
(5,30)
(10,28)
(15,16)
(20,14)
(25,10)
(30,7) and
(35,3).
We join these points with a smooth curve to get the more than ogive, as shown in the figure below.

Now, let us obtain the classes, their frequencies and the cumulative frequency from the table above.

using these values, we plot the points
(10,2) (15, 14) (20,16) (25,20)
(30,23) (35,27) (40,30)
on the same axes as in the last figure to get the less than ogive, as shown in figure below.
The abcissa of their point of intersection is nearly 17.5, which is the median.
This can also be verified by using the formula. Hence, the median profit(in lakhs) is 17.5 Rs.

Exercise-14.4
1. The following distribution gives the daily income of 50 workers in a factory.

Convert the distribution above to a less than type cumulative frequency distribution, and draw its ogive(a cumulative frequency graph).
Sol) cumulative frequency:-
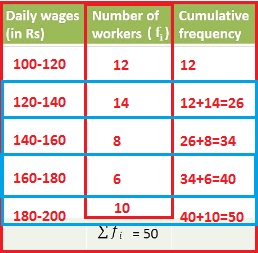
(*)Less than type cumulative frequency distribution.

(*) ogive(Cumulative freq graph):-

Graph:-

**********************************
2. During the medical check-up of 35 students of a class, their weights were recorded as follows

Draw a less than type ogive for the given data. Hence obtain the median weight from the graph and verify the result by using the formula.
sol) Less than type ogive :-
Weight is plotted in X-axis & No.of students in Y-axis

Given:- Total students is 35
.^. 𝚺Fi = 35
(*) Obtaining median weight from the graph:-
Since 𝚺Fi = 35
So,n= 35
(n/2)= (35/2) = 17.5
We draw a parallel line parallel to x-axis where number of students = 17.5

Where the line intersects it is the median = 46.5
.^. Median = 46.5
(*) Verifying result by using the formulae:-
First converting less than to normal form
Less than:-
(*) Normal Form:-


Median:-
n= 𝚺Fi = 35
n/2 = 35/2 = 17.5
Lower limit of median class(L) =46
Class-interval(h) =40-38=2
Cumulative frequency of the class before median class(cf)=14
Frequency of the median class(F)= 14
Formula:-
=> 46 + 17.5 - 14 *2
14
=> 46+ 3.5 *2
14
=> 46 + (0.25) * 2
=> 46 + 0.5
=> 46.5
**********************************
3. The following table gives production yield per hectare of wheat of 100 farms of a village.

Change the distribution to a more than type distribution, and draw its ogive.
sol) Given:- 100 farms of a village

(*) More than type distribution:-

(Graph):-
Production yield is plotted in y-axis & number of farms in the X-axis

(GRAPH):-

3. The following table gives production yield per hectare of wheat of 100 farms of a village.

Change the distribution to a more than type distribution, and draw its ogive.
sol) Given:- 100 farms of a village

(*) More than type distribution:-

(Graph):-
Production yield is plotted in y-axis & number of farms in the X-axis

(GRAPH):-

No comments:
Post a Comment